※ 작년에 약 일주일 동안 퇴근하고 진행하면서 겪었던 내용들과 느꼈던 경험들을 기록으로 남겨 놓고자 합니다.
※ 해당 블로그에서는 그 어떠한 수집된 데이터 및 요청에 의한 결과물을 별도로 제공드리지 않습니다.
※ 해당 게시물은 개인 스터디 목적으로 진행되었고 경험 공유를 위해 작성되었음을 말씀드립니다.
3부. 음성합성 (Speech synthesis)
이제 얼굴 영상은 만들었고 목소리를 만들 차례입니다. 내가 원하는 문장을 해당 타겟 인물의 목소리로 말을 할 수 있어야 합니다. 이것을 Text-to-Speech (TTS) 기술이라고 합니다. 처음엔 시중에 나와있는 TTS 서비스 중에서 윤석열 대통령과 비슷한 Voice model을 찾아 활용을 해볼까 했습니다. 그래서 찾을 수 있는 TTS 서비스를 다 들어가 보고 들어볼 수 있는 Voice model을 다 들어보고 찾아봤지만 대통령과 비슷한 목소리를 찾는 게 쉽지 않았습니다. 찾다가 그중에서 괜찮았던 TTS 서비스 업체를 아래에 링크합니다.
- 네이버 클로바 더빙 - https://clovadubbing.naver.com/
- 온에어스튜디오 - https://onairstudio.ai/
- 타입캐스트 - https://app.typecast.ai/
- Oddcast - https://ttsdemo.com/
- TTSFree - https://ttsfree.com/
3개의 비슷한 Voice를 찾기는 했지만 그중에서 그나마 비슷한 것들이지 너무 이질감이 느껴지고 타운홀에서 시연했을 때 사람들의 반응이 별로 안좋을 것 같은 생각이 들었습니다. 그래서 이왕 하는 거 제대로 해보자 하는 생각에 직접 음성 데이터를 구하고 학습해 보기로 마음을 먹었습니다.
사실 이때까진 잘 몰랐습니다. 일이 점점 커지고 있다는 것을... 😅
1. 데이터 구하기가 어렵다
찾다보니 과거에는 개인들이 수집했던 음성 데이터들을 공개해 줘서 그래도 어느 정도 쉽게 구할 수 있었던 것 같은데 해당 기술을 통해 사회적으로 심각한 사건사고가 발생되면서 그 여파로 데이터들이 다 내려가버려 구하는 게 어려워졌습니다. 공개된 음성 데이터이라도 구하면 영상을 해당 인물로 바꿔서라도 진행하려고 했는데 그마나 공개된 데이터들도 유명인, 인플루언서의 목소리가 아니다 보니 구해봤자 의미가 없었습니다.
그래서 직접 데이터셋을 수집해 보기로 합니다.

2. 데이터 구하기
찾자!! 최대한 많은 데이터를 찾자!!
누구를 타겟으로 할까? 타겟을 정하고 나면 어디서 음성을 구해야 할까?

처음에는 대한민국 사람이라면 모르는 이가 없는 유재석으로 타겟을 잡으려 했습니다. 아무래도 TV광고, 무한도전, 런닝맨 같은 예능프로 등 영상이 넘쳐나니 쉽게 구할 수 있을 것으로 생각했습니다. 하지만 음성합성을 하기 좋은 데이터는 잡음이 없고 대상의 목소리만 들어있어야 하며 전체적으로 음원파일의 데시벨이 비슷한 것이 좋습니다. 하지만 예능은 전쟁이었습니다. 치열했습니다. 출연자가 온전히 하나의 문장을 말하는 순간이 거의 없어 다른 출연자들과 오디오 겹치거나 끊기는 부분이 많았고, 생각보다 효과음이 정말 엄청나게 많았습니다.

다음으로 아이유, BTS 같은 유명가수를 타겟으로 변경하였습니다. 아무래도 앨범 음원, 유튜브에서 쉽게 데이터를 구할 수 있을 것으로 생각했는데 하지만 이것도 배경음들이 겹쳐 쉽게 활용할 수 없었습니다. 그리고 노래를 부르는 음성은 일반적인 발화와 맞지 않는 데이터라 생각되었습니다.
고민끝에 결국은 현 대통령으로 선택을 하게 되었습니다. 많지는 않지만 신년사, 연설, 국제회의, 국무회의 등의 영상들을 유튜브(https://www.youtube.com/)와 대한민국 대통령실 공식 홈페이지(https://www.president.go.kr/) 등에서 구할 수 있었습니다. 물론 이러한 연설 영상도 발언 사이에 박수소리 등의 노이즈가 있었으며 편집된 영상들이 많아 중복되지 않게 확인하는 작업이 필요했습니다.
대부분의 데이터는 유튜브를 통해 영상을 수집하였고 "윤석열", "윤석열 연설", "윤석열 신년사", "윤석열 국무회의" 등 생각할 수 있는 키워드 조합으로 겹치지 않는 영상들을 수집하였습니다. 그렇게 해서 101개 영상파일, 10.7GB, 전체 27:26:34 분량의 영상을 수집하였습니다.

3. 음성 데이터 정제
편집.. 편집.. 편집.. 끝없는 편집의 연속..
물론 수집한 영상 데이터를 바로 활용할 수는 없었습니다. 다른 유명인, 가수, 연예인의 영상보다는 적지만 그래도 상당한 노이즈가 존재했습니다. 편집툴을 이용하여 하나씩 들어보며 불필요한 Intro, Outro 부분, 편집된 부분, 다른 사람 목소리, 박수소리, 효과음, BGM 같은 노이즈 영역을 잘라내고 오직 윤석열 대통령 목소리만 나올 수 있도록 잘라내고 이어 붙였습니다.

그렇게 해서 기존 27:26:34 분량에서 15:05:42의 분량으로 줄어들었습니다.
하지만 이것또한 바로 활용할 수는 없습니다. 이제 노이즈를 제거한 음성 파일을 적당한 길이로 자르려고 합니다. 모델 학습을 잘하기 위해서는 가급적 하나의 문장이 되어야 하며 너무 짧아도 너무 길어도 좋지 않습니다.

약 15시간 분량의 음성을 다시 일일이 들으면서 문장단위로 잘라낼 수는 없기에 자동화하는 방법을 택했습니다. 제가 활용한 것은 Python Audio Library 중의 하나인 librosa를 사용했습니다.
테스트를 하다 보니 공약연설, 컨퍼런스 기조연설을 하는 대통령의 목소리는 뉴스를 진행하는 아나운서 혹은 책을 읽는 일반적인 발화와 큰 차이점이 나타났습니다. 일반적으로 우리는 말하는 속도와 음성의 높낮이는 대체적으로 고르고 어느정도의 속도가 있는 발화이지만, 연설문은 그와 다르게 주장을 펼치고 청중들에게 각인을 시켜줘야 하는게 목적이다 보니 힘차고 당찬 목소리로 높낮이 폭이 컸으며 문장이 아닌 단어 사이사이에 긴 호흡이 들어가는 부분이 많았습니다. 이렇다보니 영상마다 특성이 조금씩 달라 분리된 음성 길이가 들쑥날쑥한 경향이 있었습니다. 그래서 윤석열 대통령 음성의 데시벨, 호흡 간격 등을 파악하여 가능한 한 8초 정도의 길이로 잘라내려고 했습니다. 그리하여 기존 101개 영상 파일에서 10,034개의 음성 파일로 나뉘어 졌습니다. 많은 실험을 해보진 못했지만 음성(문장)의 길이에 따라서 결과물이 상당히 차이가 나는 것을 볼 수 있었습니다.
4. 정답 데이터셋 구축

이제 분리된 음성파일에 정답을 달아줘야 합니다. 음성합성을 하기 위한 데이터셋은 음성과 텍스트가 쌍(Pair)으로 구성되어 있습니다. 그래서 추출된 음성파일에 쌍이 되는 텍스트를 달아야 합니다. 사실, 데이터셋을 만드는데 가장 좋은 방법은 사람이 원본 음성을 들으면서 적절한 길이로 문장을 잘라내고 잘라낸 문장을 직접 타이핑해서 만드는 것입니다. 하지만 혼자서 다 하기엔 작업량이 너무 많고 귀찮고 힘들고 시간도 없고... 그래서 전문가의 도움을 받기로 했습니다. 바로 Google!! 😀
Google Cloud에서 제공하고 있는 API 중 하나인 Speech-to-Text API를 활용했습니다. 부가세 포함 약 10만원을 투자하여 결과물을 얻어낼 수 있었습니다.

Google STT 결과물을 빠르게 훑어보면서 잘못된 부분은 수정하고 너무 짧은 문장, 너무 긴 문장은 다시 한번 코드를 통해 걸러내었습니다. 그리하여 최종적으로 남은 데이터는 101개 영상파일, 10.7GB, 27:26:34에서 8,897개 음성파일, 4.1GB, 약 07:23:00으로 줄었습니다.

예상하긴 했지만 생각보다 많이 날아갔네요. librosa를 활용하여 문장을 잘라낼때 간격을 잘 조절해보면 살릴 수 있는 문장은 더 늘어날 것 같습니다. 하지만 이정도로 하고 다음 단계로 진행하였습니다.
5. 사용자 사전 (미적용)

다음으로 STT 적용 후 결과물에 대해 사전을 활용하여 텍스트를 치환하는 작업이 필요합니다. 영어 발음 사전, 수량 사전, 브랜드사전 그리고 도메인에 맞는 사용자 사전들을 구축해서 일관성 맞게 텍스트를 변환해 주면 좋습니다. 사람이 직접 타이핑하면 상관이 없겠지만 STT 등을 통해 자동화하기 위해서는 사전을 통해 치환하는 작업이 필요합니다. 하지만 저는 이 부분은 적용하지 않았습니다. 도저히 사전 구축 할 엄두가 나지 않아 바로 적용 포기하였습니다. 😭
6. Tacotron
이제 데이터셋은 구축이 끝났고 본격적으로 딥러닝 모델 훈련을 할 차례입니다. SOTA모델, 논문, 블로그들을 찾아보면서 방법론에 대해 고민해 보다가 Tacotron (https://arxiv.org/abs/1703.10135)이라는 모델을 활용해 보기로 했습니다. Google's Tacotron2, Baidu's Deep Voice3, Microsoft's PromptTTS2, Sony's BigVSAN, Princeton University's CoALA 등등.. 다양한 모델이 많지만 저자들이 스시보다 타코를 좋아하는 사람이 많아서 Tacotron이라고 정하게 된 작명센스가 맘에 들었고 audio-text pair로 End-to-End 학습이 가능한 점, 나온지 오래 된만큼 기본 메카니즘을 이해하기에 쉬운 모델이라 생각되었습니다. 그래서 공부도 할 겸 Tacotron이 적합하다고 판단했습니다.

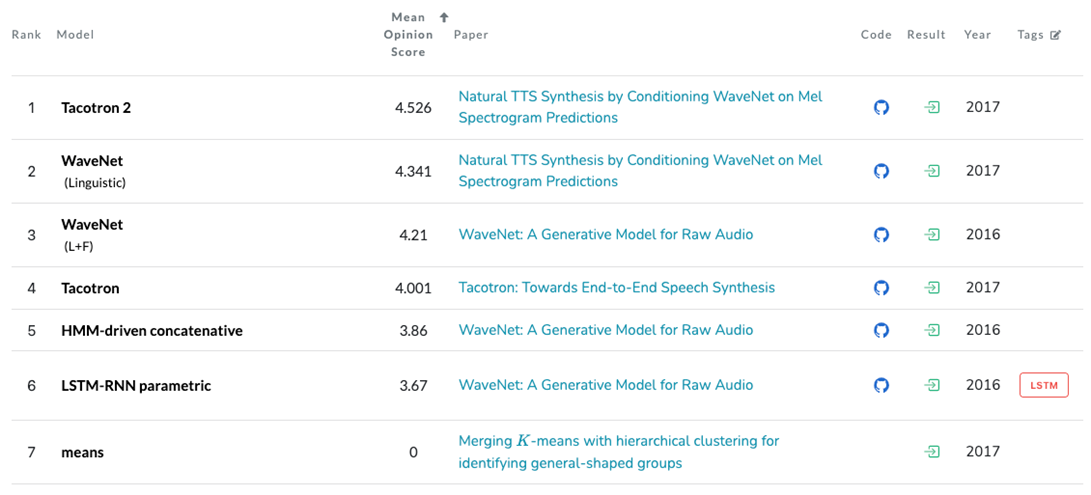


Tacotron 모델은 크게 Encoder, Decoder, Attention, Vocoder 부분으로 이루어져 있습니다. 모델에 대한 상세 설명은 생략하도록 하겠습니다. 내용이 크게 어렵지 않으니 논문을 한번 읽어보시길 추천드립니다
- Tacotron - https://arxiv.org/abs/1703.10135
- Tacotron2 - https://arxiv.org/abs/1712.05884v2
- Deep Voice3 - https://arxiv.org/abs/1710.07654
- PromptTTS2 - https://arxiv.org/abs/2309.02285
- BigVGAN - https://arxiv.org/abs/2206.04658
- BigVSAN - https://arxiv.org/abs/2309.02836
- CoALA - https://arxiv.org/abs/2309.02427
아래에서 step에 따른 alignments를 볼 수 있습니다. 너무 희미하지만 초반에는 attention이 발산하지만 step이 진행될수록 수렴하는 것을 볼 수 있습니다. (너무 미미하긴 하지만 ^^;;)
7. 결과
Speech Synthesis 결과물은 다 지워버리고 남은 게 아래 영상밖에 없습니다. 첫번째 포스팅의 전체 결과물을 참고해주세요.
8. References
- Easy is Perfect - https://melonicedlatte.com/machinelearning/2018/07/02/215933.html
- github/carpedm20 - https://github.com/carpedm20/multi-speaker-tacotron-tensorflow
- Multi-Speaker Tacotron in TensorFlow - https://carpedm20.github.io/tacotron/
윤석열 대통령 딥페이크 만들기 (1/3) - https://fuerte.tistory.com/157
윤석열 대통령 딥페이크 만들기 (1/3)
※ 작년에 약 일주일 동안 퇴근하고 진행하면서 겪었던 내용들과 느꼈던 경험들을 기록으로 남겨 놓고자 합니다. ※ 해당 블로그에서는 그 어떠한 수집된 데이터 및 요청에 의한 결과물을 별도
fuerte.tistory.com
윤석열 대통령 딥페이크 만들기 (2/3) -https://fuerte.tistory.com/158
윤석열 대통령 딥페이크 만들기 (2/3)
※ 작년에 약 일주일 동안 퇴근하고 진행하면서 겪었던 내용들과 느꼈던 경험들을 기록으로 남겨 놓고자 합니다. ※ 해당 블로그에서는 그 어떠한 수집된 데이터 및 요청에 의한 결과물을 별도
fuerte.tistory.com
윤석열 대통령 딥페이크 만들기 (3/3) - https://fuerte.tistory.com/159
윤석열 대통령 딥페이크 만들기 (3/3)
※ 작년에 약 일주일 동안 퇴근하고 진행하면서 겪었던 내용들과 느꼈던 경험들을 기록으로 남겨 놓고자 합니다. ※ 해당 블로그에서는 그 어떠한 수집된 데이터 및 요청에 의한 결과물을 별도
fuerte.tistory.com
'Portfolio' 카테고리의 다른 글
| 채용정보 크롤링 (4) | 2024.02.18 |
|---|---|
| 윤석열 대통령 딥페이크 만들기 (2/3) - DeepFaceLab, Tacotron (0) | 2024.01.30 |
| 윤석열 대통령 딥페이크 만들기 (1/3) - DeepFaceLab, Tacotron (0) | 2024.01.30 |
| 철도 예약관리 프로그램 ( Ver 3.0 ) (2) | 2010.07.08 |

